

La meilleure façon de rechercher les doublons dépend du type de doublons concernés et de ce que l’on souhaite faire des doublons trouvés:
- Rechercher intelligemment les doublons et les adresses en double (dédoublonnage) avec les DataQualityTools:
Si la méthode utilisée doit être particulièrement confortable ou si les doublons à rechercher sont des doublons difficiles à trouver, il faut pour cela utiliser absolument un logiciel spécialement adapté à ce problème. Les DataQualityTools trouvent les doublons, même lorsque ces derniers diffèrent légèrement les uns des autres. Ceci est particulièrement utile pour les listes d'adresses, où les fautes d'orthographe et les variantes d’écriture relèvent plus de la règle que de l'exception. Plus d’informations ... - Supprimer les doublons avec la commande 'distinct':
S’il s’agit de valeurs en double faciles à trouver, telles que des numéros de clients ou d'articles, et que l’objectif est de les supprimer des résultats d'une requête de base de données, vous pouvez utiliser la commande SQL 'distinct'. Plus d’informations ... - Masquer les doublons avec la commande 'group by':
S’il s’agit de valeurs en double faciles à trouver, telles que des numéros de clients ou d'articles, et que l’objectif est de les masquer des résultats d'une requête de base de données, vous pouvez utiliser la commande SQL 'group by'. Plus d’informations ... - Rechercher les doublons avec la commande 'select':
S’il s’agit de valeurs en double faciles à trouver, telles que des numéros de clients ou d'articles, et que l’objectif est de supprimer directement les occurrences trouvées de la base de données ou d’ajouter et de compléter les entrées en fonction du résultat, choisissez alors la commande SQL 'select'. Plus d’informations ...
1. Rechercher intelligemment les doublons et les adresses en double (dédoublonnage) avec les DataQualityTools dans IBM DB2
Les DataQualityTools trouvent les doublons, même lorsque ces derniers diffèrent légèrement les uns des autres. Ceci est particulièrement utile pour les listes d'adresses, où les fautes d'orthographe et les variantes d’écriture relèvent plus de la règle que de l'exception. Procédez comme suit:
- Si vous ne l’avez pas encore fait, téléchargez DataQualityTools gratuitement ici. Installez le logiciel et demandez une activation d’essai. Ainsi, vous pouvez travailler avec le logiciel pendant une semaine sans aucune restriction.
- La fonction requise se trouve dans le menu du bloc 'Dédoublonnage dans une table'. Choisissez 'Dédoublonnage universel':
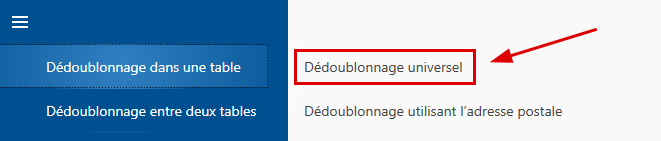
- Suite au démarrage de cette fonction, l'administration des projets apparaît à l’écran. Créez un nouveau projet avec un nom de projet quelconque et cliquez ensuite sur le bouton 'Continuer'.
- L'étape suivante consiste à sélectionner la source de données contenant les données à traiter. Pour ce faire, sélectionnez IBM DB2 dans la liste de sélection sous 'Format / Accès à'.
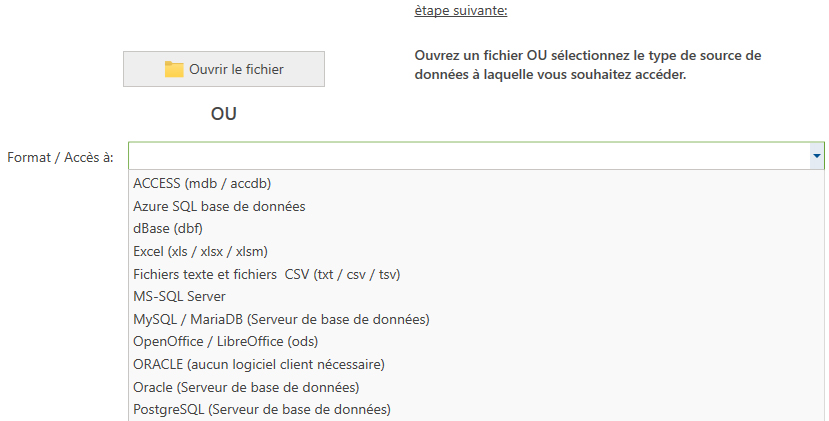
Ensuite, il faut entrer le nom du serveur de bases de données. Cliquez sur le bouton 'Connexion avec le serveur' et entrez vos données de connexion. Dans la liste de sélection correspondante, vous pouvez alors choisir la base de données et la table à traiter. - Ensuite, il faut indiquer au programme quelles sont les colonnes de la table à comparer:
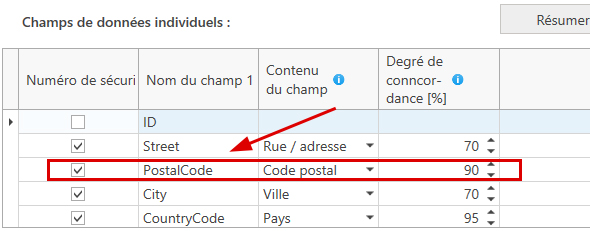
Dans cet exemple, la colonne 'Street' fait partie des colonnes à comparer. Elle contient les noms de rues, c'est pourquoi le champ 'Rue' a été sélectionné dans la liste de sélection du contenu. Une valeur minimale de 50 % a également été sélectionnée pour le degré de concordance. Le nom de la rue doit donc correspondre à au moins 50 % pour que l'entrée en question apparaisse dans les résultats.
Si nécessaire, plusieurs colonnes individuelles peuvent également être regroupées:
Le contenu des colonnes est alors fusionné dans le groupe avant la comparaison pour être comparé en même temps. - En cliquant sur le bouton 'Suivant', une boîte de dialogue s’ouvre avec d’autres options. Elles ne sont pas utiles ici.
- En cliquant sur 'Continuer', vous démarrez la recherche de doublons. Ça ne prend que quelques moments et vous obtenez un sommaire des résultats. Si le logiciel a trouvé des doublons dans la table traitée, en cliquant sur 'Afficher / modifier les résultats' permet d'obtenir un aperçu du résultat:
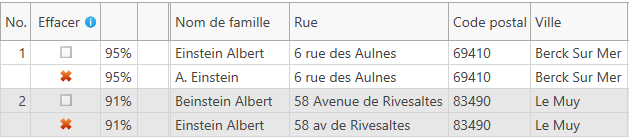
Ici, les résultats de la comparaison sont présentées sous forme tabellaire. Les enregistrements qui doivent être supprimés sont marqués ici avec une croix rouge, qui peut aussi être enlevée au besoin. - Enfin, le résultat doit être traité plus en détail. On peut par exemple sélectionner les entrées marquées pour suppression directement dans la table source de IBM DB2 avec un symbole de suppression. Pour cela, on sélectionne la fonction appropriée en cliquant d'abord sur 'Fonctions du marquage':

Puis sur 'Marquer dans la table source':
Ensuite, il faut indiquer comment le marquage doit apparaître concrètement et dans quel champ de données il doit être inscrit: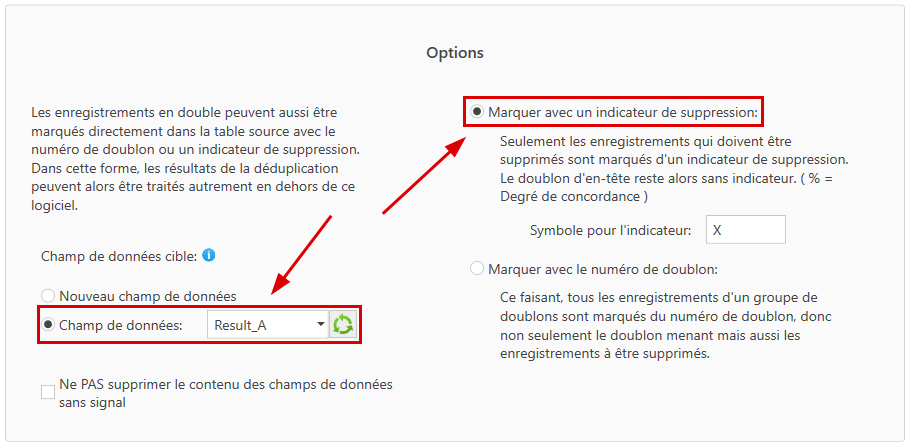
2. Supprimer les doublons avec la commande 'distinct' dans IBM DB2
Supposons qu’il faille identifier tous les numéros d'article commandés par un même client à partir de la table contenant les articles commandés, de sorte que chaque numéro d'article ne puisse être attribué qu'une seule fois à un client. La requête dans la base de données pourrait ressembler à ceci:
SELECT DISTINCT customer_id, article_no
FROM customer_articles
ORDER BY customer_no, article_no
Le terme 'distinct' fait référence à toutes les colonnes spécifiées dans le champ 'select'. Au bout du compte, ici aussi chaque numéro d'article est listé avec chaque numéro de client, mais chaque combinaison de numéro d'article et de numéro de client n'est mentionnée qu'une seule fois. En complément de la commande 'into', vous pouvez également corriger les entrées en doubles dans la table:
SELECT DISTINCT customer_id, article_no
INTO table_new
FROM customer_articles
ORDER BY customer_no, article_no
Les données nettoyées des doublons sont listées dans une nouveau table.
3. Masquer les doublons avec la commande 'group by' dans IBM DB2
Supposons qu’il faille identifier les numéros d'article à partir de la table contenant les articles commandés, de sorte qu’au final, chaque numéro d'article n’apparaisse qu’une seule fois. La requête dans la base de données pourrait ressembler à ceci:
SELECT article_no, COUNT(*), SUM(revenue)
FROM invoice_articles
GROUP BY article_no
ORDER BY COUNT(*), article_no
En plus du numéro d'article, cette requête permet d’afficher le nombre d'entrées qui contiennent ce numéro d'article et le total des ventes pour ces entrées.
4. Rechercher les doublons avec la commande 'select' dans IBM DB2
Les doublons évidents, donc ceux où les caractères sont identiques sauf pour la casse, sont faciles à trouver avec des requêtes SQL. Avec la requête suivante, par exemple, IBM DB2 retourne tous les enregistrements qui coïncident avec le contenu du champ de données 'nom':
SELECT tab1.id, tab1.name, tab2.id, tab2.name
FROM tablename tab1, tablename tab2
WHERE tab1.name=tab2.name
AND tab1.id<>tab2.id
AND tab1.id=(SELECT MAX(id) FROM tablename tab
WHERE tab.name=tab1.name)
Comme on peut voir, cette requête SQL a besoin d'une colonne avec un ID qui identifie chaque enregistrement clairement, pour assurer qu'un enregistrement ne sera pas comparé avec lui-même. En plus, cet ID est requis pour assurer que l'enregistrement avec le plus grand ID n'apparaîtra que dans la colonne 'tab1.id', et non aussi dans la colonne 'tab2.id'. De cette façon, on assure que l'enregistrement du groupe de doublons avec le plus grand ID ne sera pas supprimé. Les IDs des enregistrements qui seront supprimés sont écrits dans la colonne 'tab2.id'. Voici les résultats incorporés dans une commande DELETE pour IBM DB2:
DELETE FROM tablename
WHERE id IN
(SELECT tab2.id
FROM tablename tab1, tablename tab2
WHERE tab1.name=tab2.name
AND tab1.id<>tab2.id
AND tab1.id=(SELECT MAX(id) FROM tablename tab
WHERE tab.name=tab1.name))
Cette commande SQL peut aussi être facilement élargie pour inclure, en plus du contenu du champ de données 'nom', d'autres champs de données dans la comparaison, par exemple, ceux qui contiennent l'adresse postale.
Vous pouvez en lire plus sur les autres possibilités offertes par SQL pour la recherche de doublons flous dans l'article 'Trouver les doublons flous avec SQL'. Ce problème ne peut être vraiment résolu qu’avec des outils spécialisés, qui offrent une recherche de doublons tolérante aux erreurs, comme par exemple DataQualityTools.